Quinlan (1993) describes a post-processing technique used for numeric predictions that adjusts them using information from the training set.
Let’s say you have some model with a numeric outcome \(y\) and a vector of predictors \(\boldsymbol{x}\). We’ve fit some model to the training set and we have a new observation with predictors \(\boldsymbol{x}_0\); the model’s prediction is \(\widehat{y}_0\).
This method finds the \(K\)-nearest neighbors to \(\boldsymbol{x}_0\) from the training set (denotes as \(\boldsymbol{x}_1\ldots \boldsymbol{x}_K\)) and their corresponding predictions \(\widehat{y}_i\). The distances from the new sample to the training set points are \(d_i\).
For the new data point, the \(K\) adjusted predictions are:
for \(i=1\ldots K\). The final prediction is the weighted average the \(\widehat{a}_i\) where the weights are \(w_i = 1 / (d_i + \epsilon)\). \(\epsilon\) is there to prevent division by zero and Quinlan defaults this to 0.5.
Suppose the true value of the closest neighbor is 10 and its prediction is 11. If our new value \(\boldsymbol{x}_0\) is over-predicted with a value of 15, we end up adjusting the prediction down to 14 (i.e., 10 + (15 - 11)).
This adjustment is an integral part of the Cubist rule-based model ensemble that we discuss in APM (and will later in this book). We’d like to apply it to any regression model.
To do this in general, I’ve started a small R package called adjusted. It requires a fitted tidymodels workflow object and uses Gower distance for calculations.
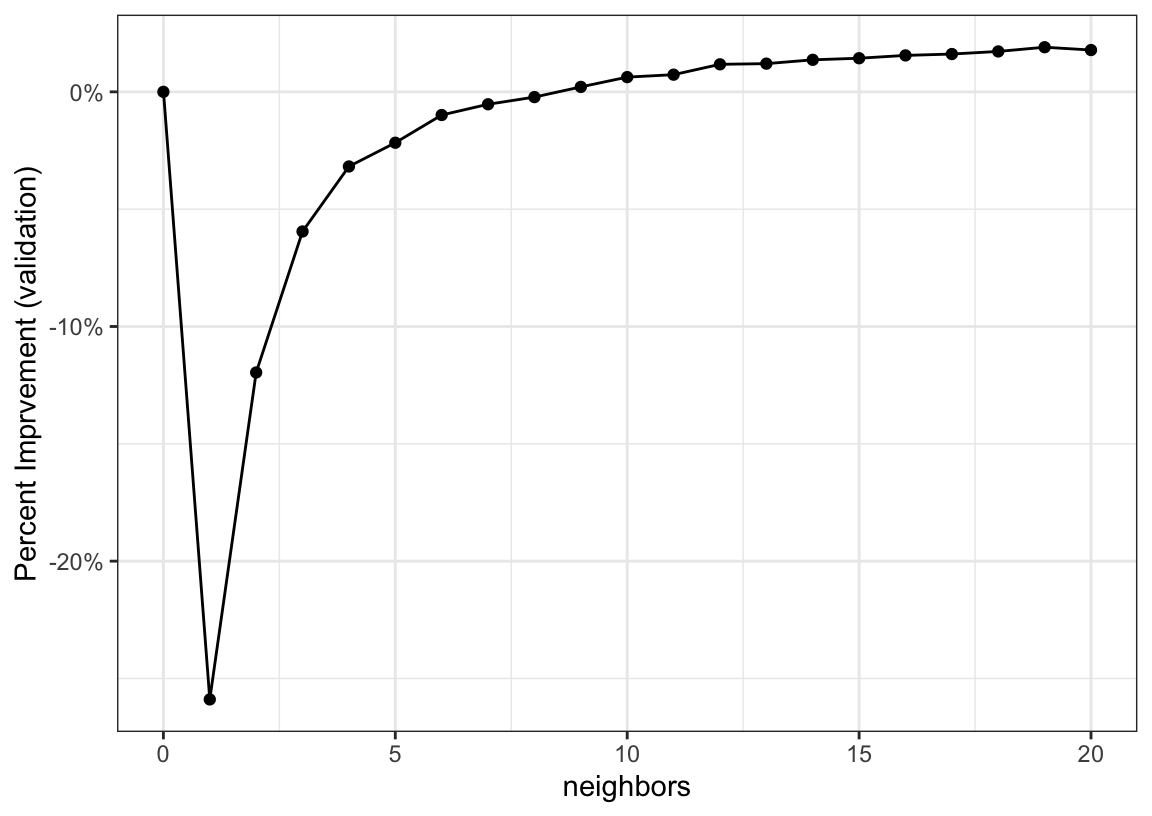
The RMSE profile looks fairly common (based on our experiences with Cubist). The 1-NN model is awful since it is over-fitting to a single data point. As we increase the number of neighbors the RMSE drops and eventually surpasses the results without any adjustment:
For these data, the best case is a 1.9% improvement in the RMSE. That’s not a game changer, but it is certainly helpful if every little bit of performance is important.
I made this package because the tidymodels group is finally focusing on post-processing: things that we can do to the model predictions to make them better. Another example is model calibration methods.
Our goal is to let you add post-processing steps to the workflow and tune/optimize these in the same way as pre-processing parameters or model hyperparameters.