New caret version with adaptive resampling
A new version of caret is on CRAN now.
There are a number of bug fixes:
- A man page with the list of models available via
trainwas added back into the package. See?models. - Thoralf Mildenberger found and fixed a bug in the variable importance calculation for neural network models.
- The output of
varImpforpamrmodels was updated to clarify the ordering of the importance scores. getModelInfowas updated to generate a more informative error message if the user looks for a model that is not in the package’s model library.- A bug was fixed related to how seeds were set inside of
train. - The model “
parRF” (parallel random forest) was added back into the library. - When case weights are specified in
train, the hold-out weights are exposed when computing the summary function. - A check was made to convert a
data.tablegiven totrainto a data frame (see this post).
One big new feature is that adaptive resampling can be used. I’ll be speaking about this at useR! this year. Also, while I’m submitting a manuscript, a pre-print is available at arxiv.
Basically, after a minimum number of resamples have been processed, all tuning parameter values are not treated equally. Some that are unlikely to be optimal are ignored as resampling proceeds. There can be substantial speed-ups in doing so and there is a low probability that a poor model will be found. Here is a plot of the median speed-up (y axis) versus the estimated probability of model at least as good as the one found using all the resamples will occur.
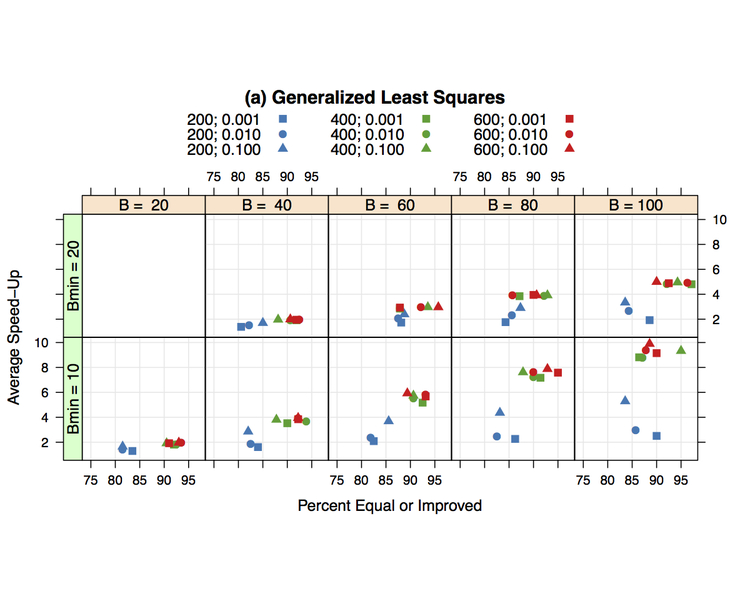
The manuscript has more details about the other factors in the graph. One nice property of this methodology is that, when combined with parallel processing, the speed-ups could be as high as 30-fold (for the simulated example).
These features should be considered experimental. Send me any feedback on them that you may have.
(This article was originally posted at http://appliedpredictivemodeling.com)